概要
ソシャゲには大量にキャラがいて、攻略wikiはキャラごとに個別ページが作られていることが多いです。
なでしこを使って、これを一覧表にまとめましょう。
目標手順(ざっくり)
全個別ページのキャラ名・URLを配列にいれる
全個別ページをローカルにダウンロードする
各ページから文字列処理で必要な部分を取り出す
表に加工してエクセルに貼り付けする
できあがり
使用する関数
・SをSJIS変換
元の文字コードを自動判別してSJISに変換します。
なでしこ1で文字列処理する場合、SJIS変換しておけばOKです。
・SをURLエンコード
日本語をURL欄にあらわれるアレの形(下記に例)に変換します。
文字コードを変えてから実行する必要があるかもしれません。
例)「なでしこ」をURLエンコード //→ %82%C8%82%C5%82%B5%82%B1
例)「なでしこ」をUTF8N変換してURLエンコード //→ %E3%81%AA%E3%81%A7%E3%81%97%E3%81%93
・URLをFILEへHTTPダウンロード
・URLからHTTPデータ取得
URLを指定してファイルに保存する命令と変数に入れる命令です。
HTMLファイルをDLして処理する場合、SJIS変換が必要になるでしょう
例)urlからHTTPデータ取得してSJIS変換
例)urlをhtmlfileへHTTPダウンロード。htmlfileを開いてSJIS変換
・SからAのタグ切り出し
文字列から特定のタグを切り出して配列に入れます。
反復と組み合わせて使います。
imgタグのような、閉じないタグには使用できません(※ の書き方をしている場合はできる様子)
・SからAの階層タグ切り出し
特定のタグの下にあるタグを切り出します。
・SのAからBをタグ属性取得
Aタグのhref属性や、imgのsrc属性を取り出すなどに使います。
例)htmlの「A」から「href」をタグ属性取得
・Sからタグ削除
文章からhtmlタグを削除します。
キャラ個別ページの取得
今回はあやかしランブル!くんの攻略wikiからスキル表などを作っていきます。
全個別ページのキャラ名・URLを配列にいれる
wikiにはキャラ一覧テーブルがあるのでそのページのhtmlをダウンロードします。
ここ→ 星5キャラクター一覧 - あやかしランブル!(あやらぶ)攻略 Wiki
単にテーブルタグに入っていれば、
「table」のタグ切り出し
でターブルタグを取得できます。
テーブルタグが入れ子になっている場合は
「table/table」の階層タグ切り出し
を使ってテーブルタグの中のテーブルを取り出します。
よくわからなければ切り取りなどで必要なテーブルの手前を削除してから作業する方法もあります。
その後、テーブルタグ内にあるAタグを取り出して、キャラ名とページURLを表にします。
結果とは変数
url=「https://ayarabu.wikiru.jp/?%E2%98%855」 //★5のキャラ一覧ページ
原文=urlからHTTPデータ取得してSJIS変換 //SJISにしようね
原文から「table/table」の階層タグ切り出し //ページの構造による
反復
もし回数が1ならば //1個目のテーブルタグから
対象から「a」をタグ切り出しして反復 //Aタグを取り出す
リンク先=対象の「a」から「href」をタグ属性取得してトリム
キャラ名=対象からタグ削除 //Aタグのテキスト部分
「{キャラ名}{タブ}{リンク先}」を結果に一行追加
結果をメモ記入
実行結果
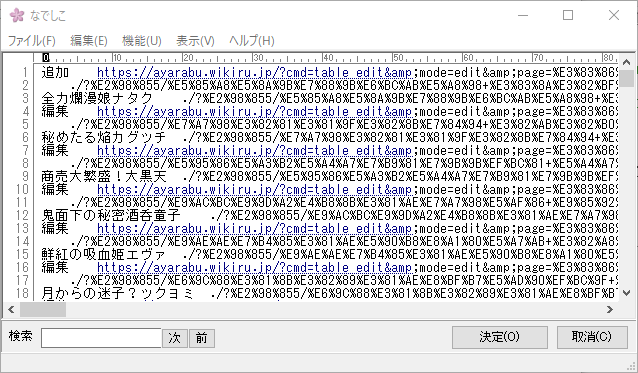
しかしこのテーブルの中には表自体を編集するボタンがリンクとしてあったり、画像がリンクになっているためきれいな結果にはなりませんでした。
上記の例では一行追加の前に以下の例外処理を入れて良しとしました。
もしキャラ名が空ならば続ける //例外処理
もしキャラ名が「編集」ならば続ける //例外処理
もしキャラ名が「追加」ならば続ける //例外処理
「{キャラ名}{タブ}{リンク先}」を結果に一行追加
手直しした結果
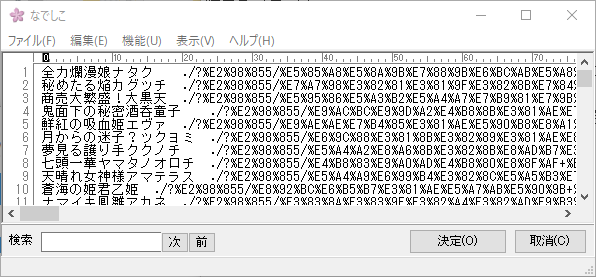
「{キャラ名}{タブ}{リンク先}」の一覧ができたので、この表を使っていきます。
プログラムを手直しした時に再度ダウンロードしなくて済むように表はファイルに保存しておきます。
結果を「一覧表.txt」へ保存
おわり
全個別ページをローカルにダウンロードする
先ほどの結果をTSV取得して反復で処理します。
各ページのURLは「./なんたらかんたら」となっているので、トップページからの相対パスです。
AをBでURL展開
という命令があるので、URLを生成してダウンロードします。
次の工程で文字コードの問題があるので、HTTPデータ取得してSJIS変換して保存しますかね……
結果は「一覧表.txt」を開く //「{キャラ名}{タブ}{リンク先}」の一覧
結果をTSV取得して反復
ファイル名=「{母艦パス}wiki個別ページ\{対象[0]}.txt」
URL=対象[1]を「https://ayarabu.wikiru.jp/」でURL展開
URLをHTTPデータ取得してSJIS変換
それをファイル名へ保存
1秒待つ
キャラ名にファイル名として使えない文字がある場合、
Sの文字列ファイル名変換
という命令があるのでファイル名に使える文字にすることができます。
キャラ名がそもそもSJISじゃない場合はなでしこ1ではどうにもできない感じです。
短時間に連続ダウンロードするとトテモシツレイにあたるので、1秒待つを入れています。
適切かどうかは自信がないです。
各ページから文字列処理で必要な部分を取り出す
次はダウンロードしたhtmlから基本情報とスキルテーブルを取り出すのですが、ここで問題が発生します。
テーブルタグの中身がセル結合だらけで複雑なのです。
↓スキルが書いてある部分(セル結合は予想)

切り出しがかんたんなのはwikiの編集ページです。
先ほどの個別ページのかわりに編集画面をダウンロードして、textareaタグの中身をローカルに保存します。
↓wikiの該当ページの編集画面

「|」で区切られた表になっているので、いくらか簡単です。
記述を加工するいろいろ
基本情報テーブルの原文はこんな感じ。
|CENTER:480|CENTER:100|CENTER:150|c
|&attachref(カグツチ.png,zoom,480x0);|~名前|秘めたる焔 カグツチ|
|~|~レアリティ|★5|
|~|~属性|&color(#ff0000){火};|
|~|~武器種|斬撃|
|~|~隊列|前衛|
|~|~タイプ|攻勢|
レア度が5で、属性は火、武器は斬撃で隊列は前衛、タイプは攻勢。
この情報をワイルドカードマッチと抽出文字列でとりだします。
・「|~レアリティ|★(#)」でワイルドカードマッチ
このゲームのレアリティは★1~★5です。
ワイルドカードの # は数値1文字です。
( )でくくって抽出文字列で取り出します。
・「|~属性|*([光闇火水風])」でワイルドカードマッチ
このゲームの属性は「光闇火水風」のいずれかです。
[光闇火水風]を ( )でくくれば抽出文字列で取り出せます。
wikiの色指定部分はいらないので*で除外。
・「|~武器種|([=斬撃|刺突|打撃|射撃|術具])|」でワイルドカードマッチ
このゲームの武器種は 斬撃、刺突、打撃、射撃、術具の5種類です。
[=a|b]でワイルドカードマッチがorの記述方法となります。
前衛・中衛・後衛は「|~隊列|([前中後]衛)|」でワイルドカードマッチ。
タイプは「|~タイプ|([=攻勢|耐久|知略|均衡|救護]*)|」でワイルドカードマッチ。
なでしこは正規表現も使えるので、正規表現マッチでもいいでしょう。
正規表現を使うときの注意
ワイルドカードマッチの「*」と正規表現の「.*」はにているようで動作が異なります。
正規表現の.*は最長一致となります。
正規表現の.*?でワイルドカードマッチと同じような結果になります。
正規表現の|はキーワードなので\|にする必要があります。
//最初の縦棒の間にあるものを調べたい
「|a|b|c|d|」を「|*|」でワイルドカードマッチして表示 //→ |a|
「|a|b|c|d|」を「\|.*\|」で正規表現マッチして表示 //→ |a|b|c|d|
「|a|b|c|d|」を「\|.*?\|」で正規表現マッチして表示 //→ |a|
記号が渋滞するのでワイルドカードの方が好きです。
エクセルに貼り付けする
あちこちから集めたデータをタブ区切りのテキストにします。
配列に入れた場合は表TSV変換でタブ区切りのテキストになります。
あとはコピー(なでしこの命令)してエクセルに貼り付け(自力)して出来上がり!

1スキル1行の表にした結果、294キャラで2087行になりました。